Predicting CO₂ Dispersion with Vertex AI
Preview
This section is the technical complement to the previous UX case study for EcoRoute : a tool designed to support more sustainable logistics decisions.
Here, I document how I used Google Vertex AI to build a predictive model capable of estimating CO₂ dispersion based on transport type and real-time weather conditions.

Tools
Google Vertex AI (AutoML, Tabular)
Google Cloud Platform
Python (dataset simulation, data generation)
CSV / Google Sheets
Figma
Role
AI Model Builder
Dataset Designer
Tool Tester
Date
May 2025
NB: Since I’m working with the trial version of Vertex AI, the model won’t always be available online, so I decided to document the whole process with screenshots.
Technical Objective
The goal was to develop a no-code predictive model able to estimate how much CO₂ is actually dispersed into the atmosphere during transport, taking into account:
the weather conditions
the characteristics of the transport vehicle
Dataset
The For this prototype, I created a simulated dataset with the help of ChatGPT, made up of 1,000 hypothetical routes between European cities.
The variables included:
Departure and arrival cities
Type of vehicle (Truck, Train, Ship, Plane)
Distance in km
Atmospheric pressure (hPa)
Humidity (%)
Wind speed (km/h)
Theoretical CO₂ emissions (kg)
Estimated dispersed CO₂ (kg) → model target variable
Estimated transport cost (€)
The dataset was saved in CSV format and structured to be compatible with Vertex AI.
Steps in Vertex AI
I created a new project in Google Cloud and activated Vertex AI
I uploaded the dataset as a tabular file
I selected the column
CO2_Dispersa_Stimata_kgas the target, using the Regression optionI let Vertex AI automatically select the input variables
I started the training with AutoML, without writing any code
Results (First Dataset)
The first model was trained successfully and showed good results in terms of prediction accuracy:
MAE (Mean Absolute Error): 0.524 kg
MAPE (Mean Absolute Percentage Error): 14.1%

However, the feature importance analysis revealed a critical issue:
the model relied almost entirely on the Teorical_Emissions_kg variable, while weather conditions (such as wind, pressure, and humidity) had almost no impact.

Something was clearly off.
This result, although statistically “perfect”, highlighted a limitation in the initial dataset design:
weather data was present, but not strong enough in the formula used to generate the target, so the model learned to ignore it.
This experience helped me realize an important lesson in machine learning:
a good model is not only about the numbers, but also about the quality and balance of the features it uses.
For this reason, I decided to regenerate the dataset and change the formula, so that the influence of weather conditions would be stronger and better aligned with the project’s goal of promoting environmentally conscious logistics.
Results (Second Dataset)
After modifying the dataset to give more weight to weather conditions, the second model showed improved accuracy and a slightly greater sensitivity to environmental variables.
The Teorical_Emission_kg feature remained the most influential, but wind, pressure, and humidity began to contribute to the prediction.
This confirmed how much the structure of a dataset affects the learning process of a model, and how even small changes in feature design can influence AI behavior and decision-making.


Deploy & Test
At this point, I deployed the model and started testing it.
Below is a manual prediction test performed in Google Vertex AI.
Input:
Rome → Berlin | Truck | 1500 km | 1015 hPa | 70% humidity | 25 km/h wind | 500 kg theoretical CO₂ | €420 cost

Output:
Estimated dispersed CO₂: 457.29 kg
Prediction interval (95%): [447.89 – 460.91] kg
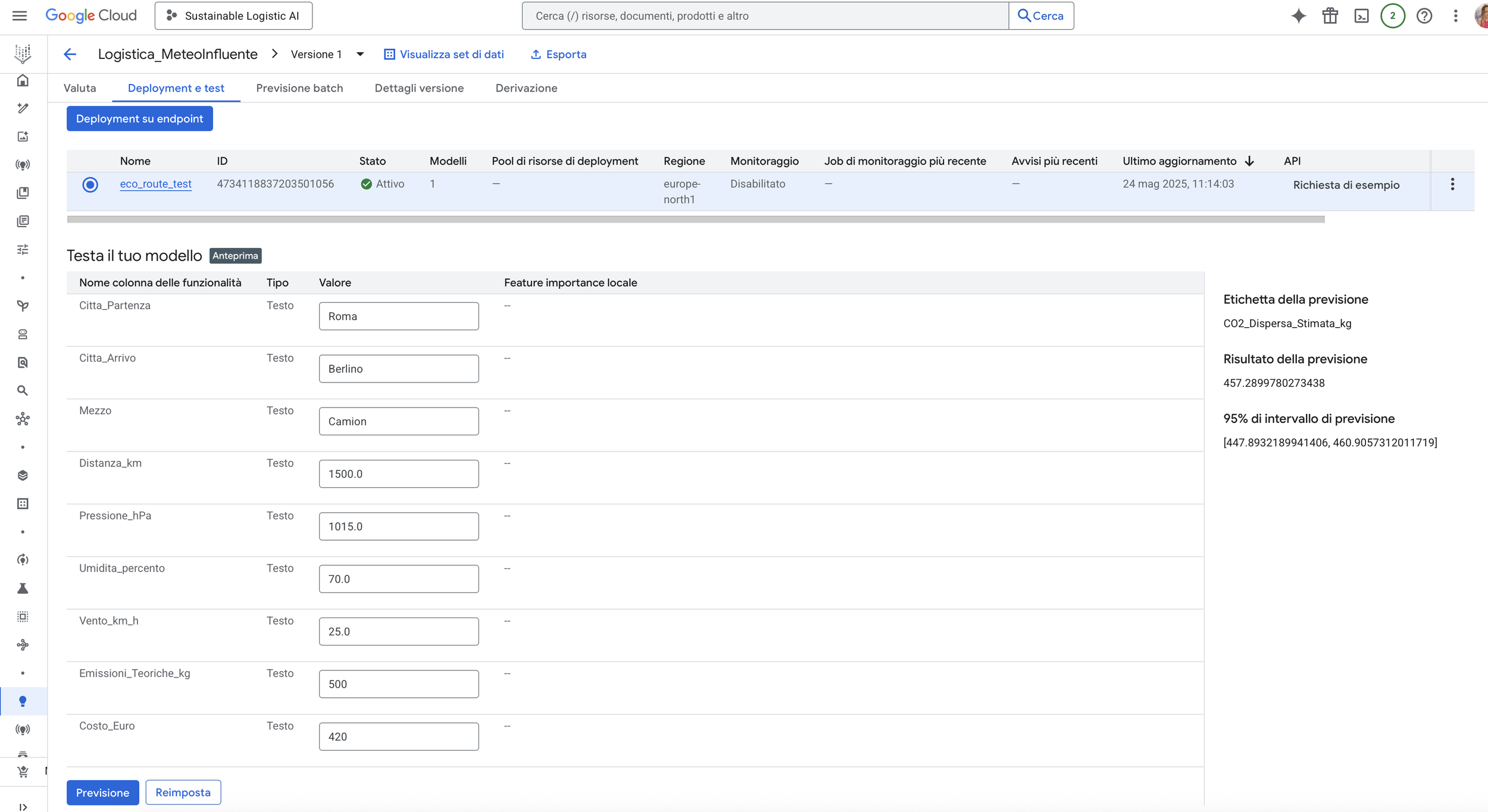
The model estimated 457.29 kg of dispersed CO₂ based on the route, vehicle type, and weather conditions.
This test illustrates the practical use of the trained model to support logistics decisions with a lower environmental impact.
Key Takeaways
UX & AI work together → UX helps shape how AI tools are built and used
Good data = good model → Dataset structure directly impacts results
No-code ≠ no thinking → Tools like Vertex AI still require design logic
Iterate and improve → The first model worked, but didn’t align with the goal
Process is key → Every choice, even the wrong ones, adds value